Johns Hopkins University
NeurIPS 2025 (Spotlight)
*Equal Contribution, †Corresponding Author
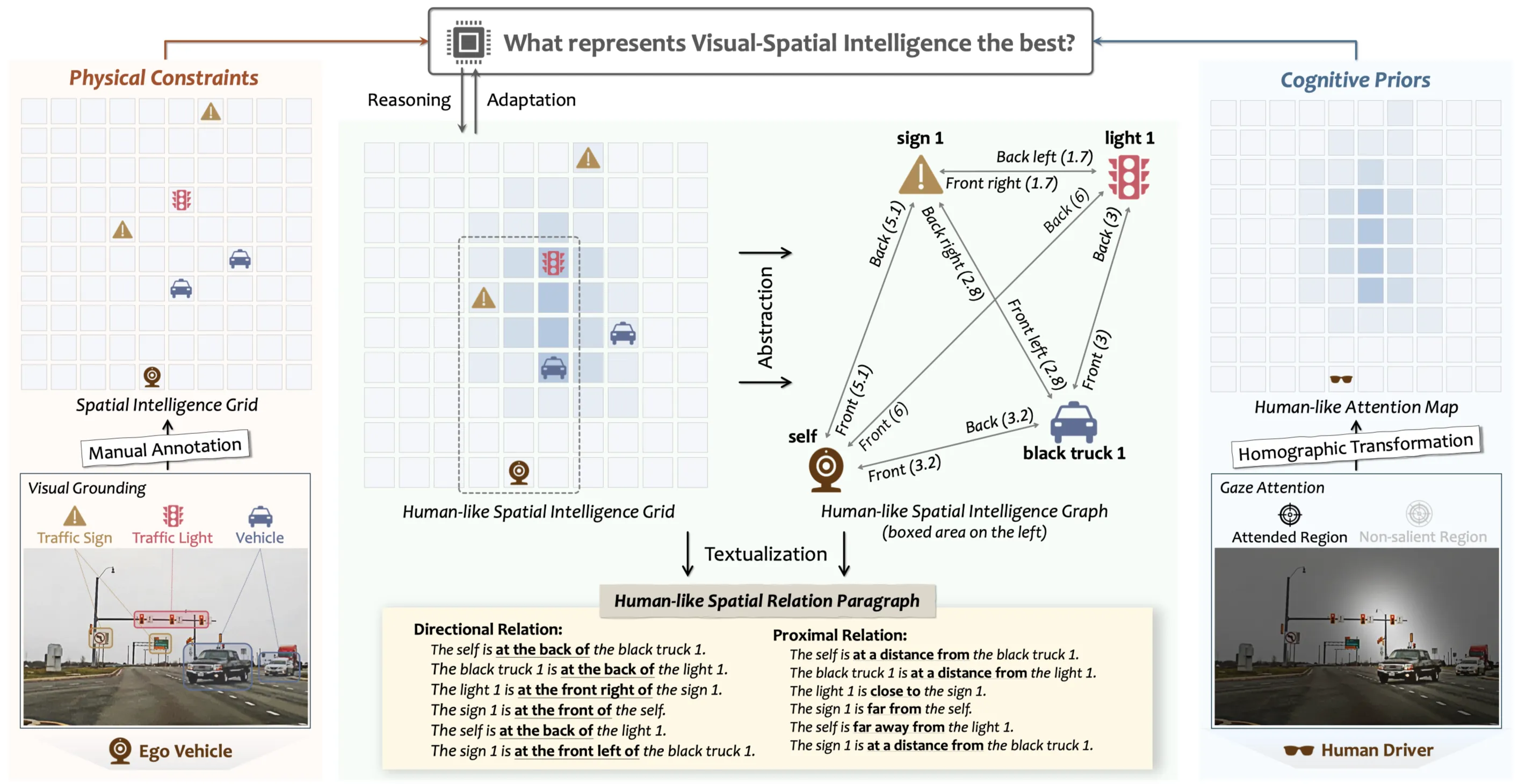
How to encode visual-spatial intelligence (VSI) into representative and informative features remains an open challenge. Instead of representing VSI through Visual Question Answering (VQA)-style solely, we introduce spatial intelligence grid (SIG): a structured, grid-based data schema that embeds geometrical spatial relationship among objects along with physical priors in human world, as a complementary representation. We further derive a set of SIG-informed evaluation metrics that rigorously quantify a model’s true VSI capabilities. In few-shot in-context learning experiments on state-of-the-art multimodal LLMs (e.g. GPT-4o, Gemini-2.5-Pro), SIG yields consistently larger, more stable, and more comprehensive improvements across all VSI metrics compared to VQA-style representations, demonstrating its potential as a novel data schema for learning VSI. Based on SIG, we create SIGBench, a benchmark containing 1.4K driving frames annotated with ground-truth SIG labels and human gaze attention, supporting both grid-based machine VSI tasks and human-like attention-driven VSI tasks in autonomous-driving scenarios.
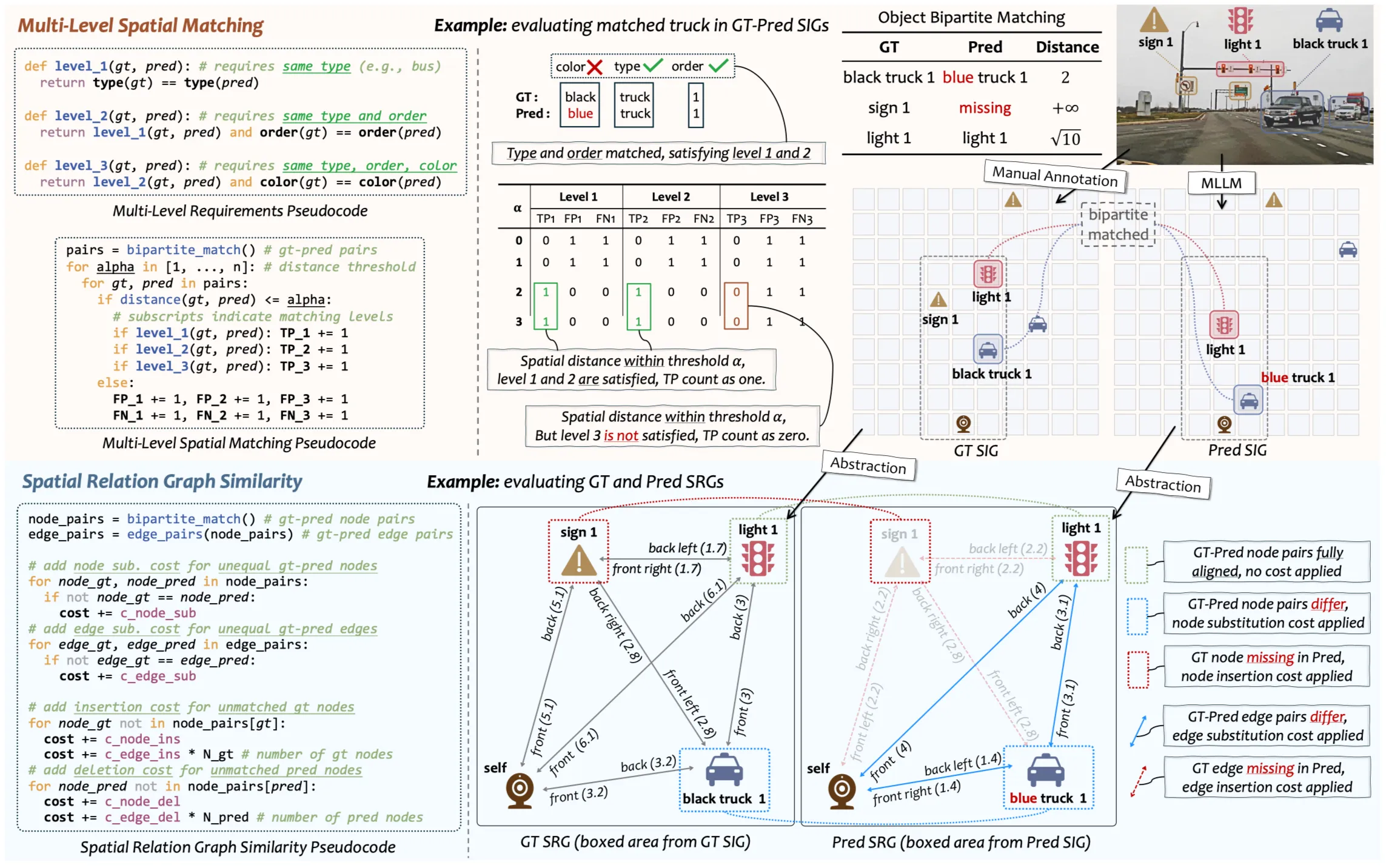
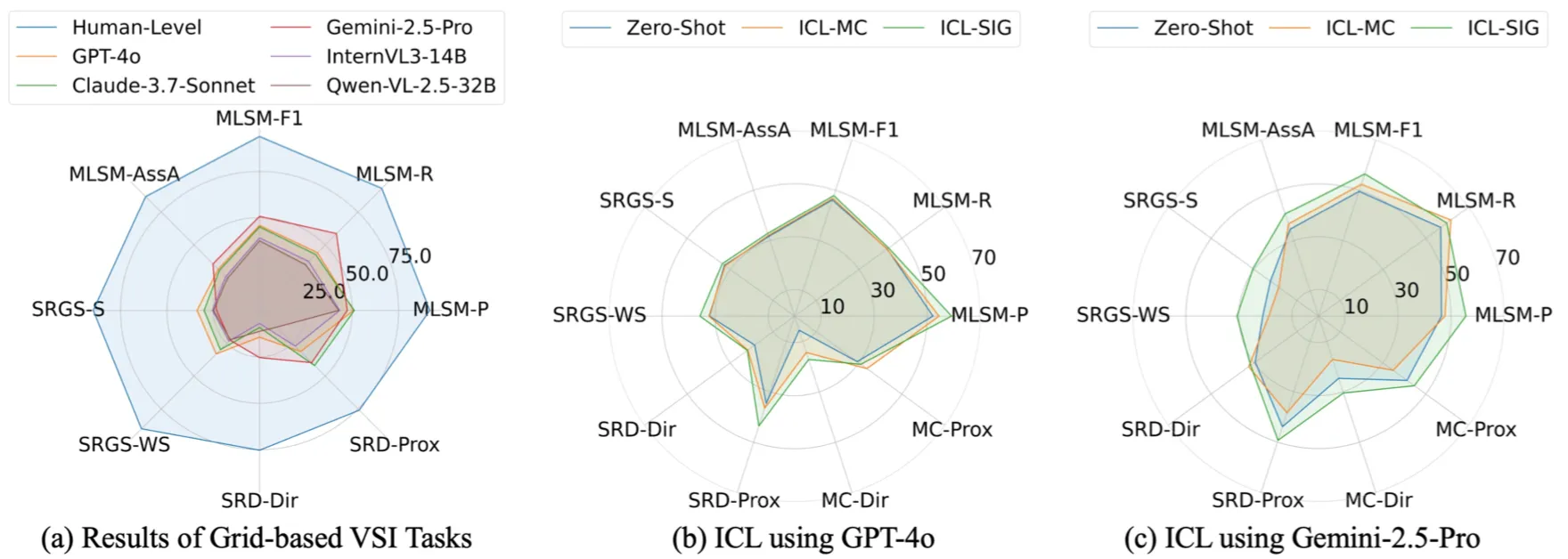
Based on SIG, we can extract a directed spatial relation graph (SRG) that describes the spatial relation (direction+distance in grid) of each object and spatial relation paragraph (SRP) that describes spatial relation of each object within a text manner. To quantitatively assess the a model’s VSI, we propose three novel evaluation metrics: Multi-level spatial matching (MLSM), spatial relation graph similarity (SRGS) and semantic relational distance (SRD). MLSM compares object positions directly within the SIG representation, capturing absolute localization accuracy. SRGS measures both node-wise and edge-wise correspondence between predicted and ground-truth (GT) SRG, emphasizing relation classification and structure. SRD computes a semantic relational distance between predicted and ground-truth prepositions in SRP, evaluating the fidelity of both directional and proximal relations.
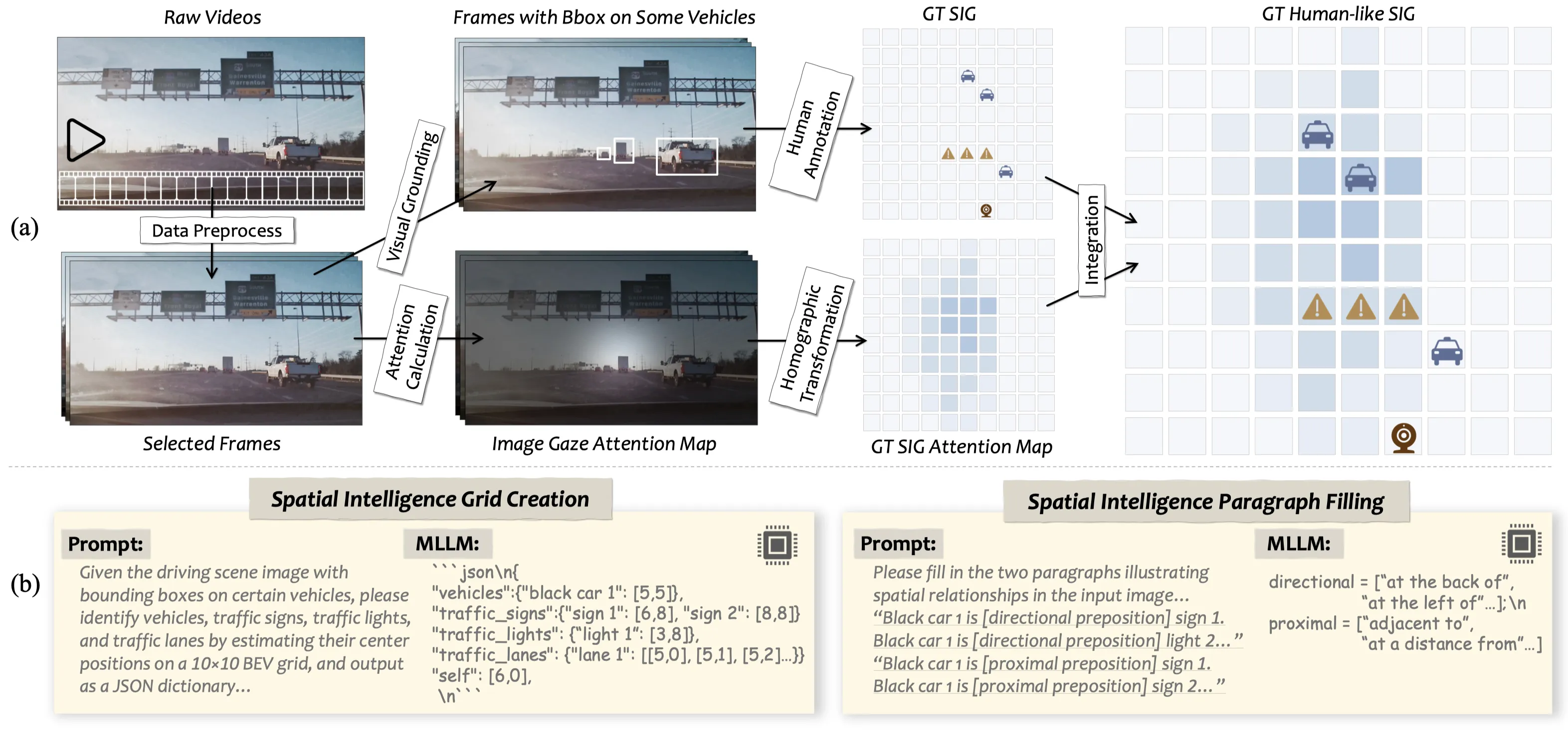
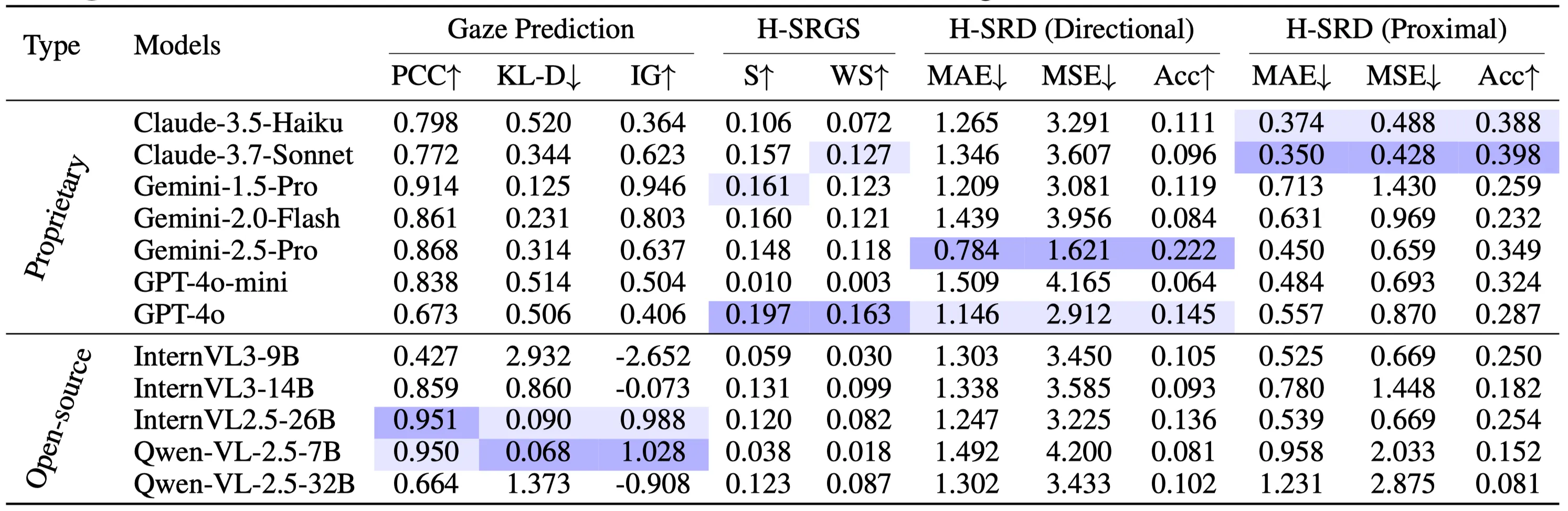
We introduce SIGBench, a benchmark for quantifying both grid-based and human-like VSI in MLLMs within AD scenario. SIGBench comprises 1,423 frames, each annotated with (i) SIG and human-like SIG, (ii) SRP and human-like SRP and (iii) a gaze attention map in image size. SIGBench contains two main task clusters: grid-based VSI tasks: spatial intelligence grid creation (SIGC) and spatial relation paragraph filling (SRPF) and human-like VSI tasks: human-like SIGC and SRPF, and gaze prediction.
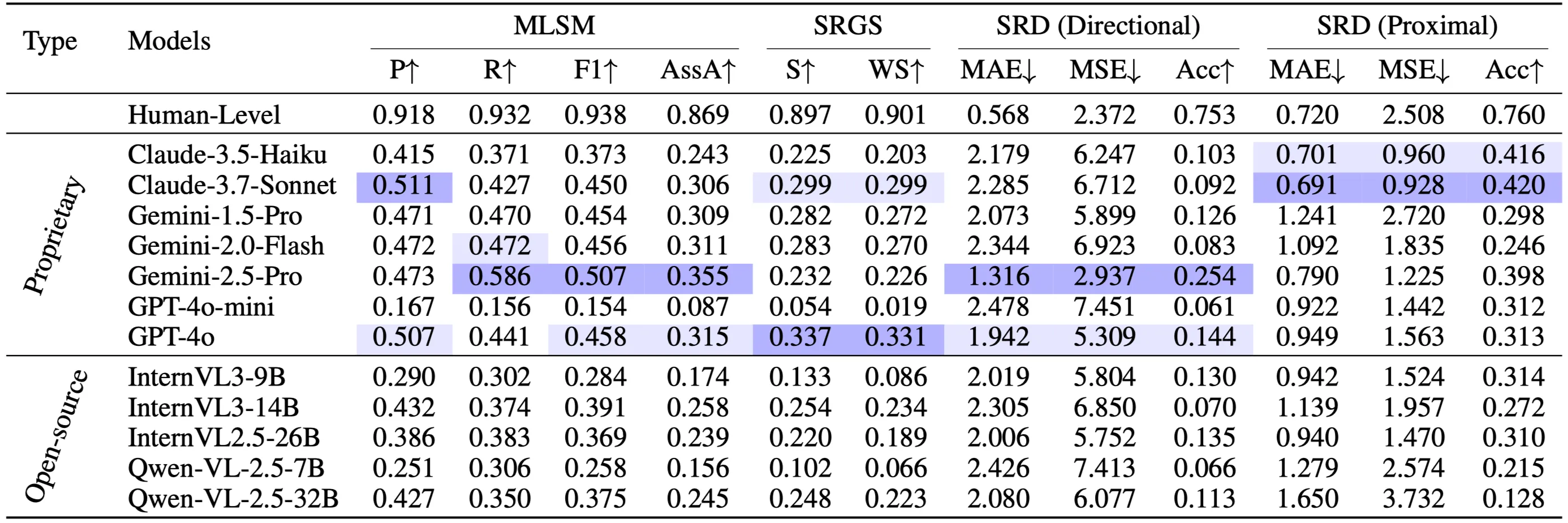
We evaluate several top-tier MLLMs on SIGBench mainly from five modal families: 1) open-source models such as InternVL and Qwen-VL; 2) Proprietary models including OpenAI GPT, Google Gemini and Anthropic Claude. We conduct both SIG-based and MC(VQA)-based In-context Learning (ICL) on GPT-4o and Gemini-2.5-Pro.

The author team would like to share the sincere thank to Wei Zhang from U.S. Department of Transportation (USDOT) for providing the valuable U.S. Federal Highway Administration driving dataset, based on which we construct our proposed benchmark. The author team also appreciate the valuable suggestions from Junyue Jiang, Linshen Liu and Yibo Zhao during the discussion about this project.
@inproceedings{wu2025towards,
title = {Towards Physics-informed Spatial Intelligence with Human Priors: An Autonomous Driving Pilot Study},
author = {Wu, Guanlin and Su, Boyan and Zhao, Yang and Wang, Pu and Lin, Yichen and Yang, Hao Frank},
booktitle = {The Thirty-Ninth Annual Conference on Neural Information Processing Systems (NeurIPS)},
year = {2025}
}